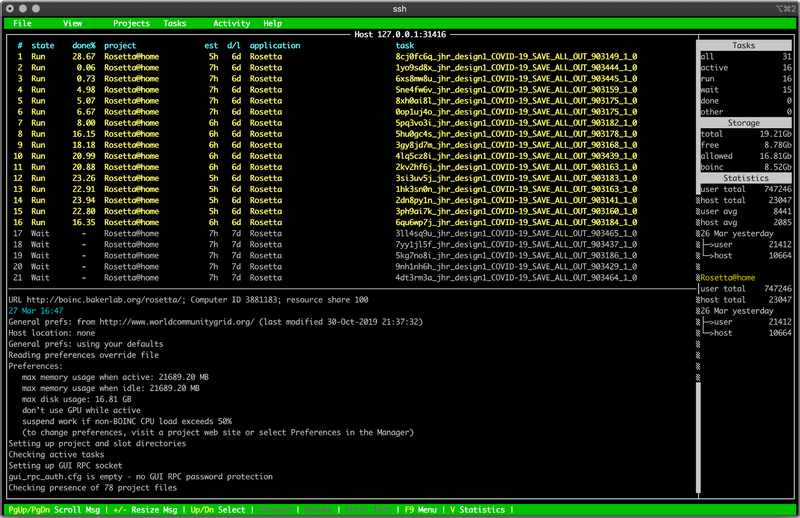

Or, “How to contribute 4.5 CPU-years of compute to your favorite distributed project using someone else’s money.”
Because GCE gives you a $300 free trial of their services, and you can use those to contribute CPU cycles to Rosetta@Home, Folding@Home, or any other “distributed grid computing” project you wish!

Even if you don’t have a fancy compute server, don’t worry - you can use someone else’s, for free*!
* At least for a while.
How? Keep reading!
Distributed Citizen Computing: SETI, Folding@Home, BOINC, and more!
If you’ve never heard of distributed compute, SETI, BOINC, Folding@Home, etc, well, I’m mildly surprised you’re reading my blog. But, if you’re some sort of science group doing something interesting (looking for aliens, doing protein folding simulation, large scale climate simulation, or something along those lines) that requires a lot of compute cycles, it’s really, really expensive to buy the servers for doing that. So, you convince other people to donate their computer cycles by putting in scoring systems, leaderboards, and other various gamification aspects that turn contributing compute cycles into a hobby.
And people will get into it and have giant farms of servers for this stuff! Long ago, it used to be a bit more crazy than it is today, and apparently some people with basement rooms full of servers, venting hot air directly outside, had long and awkward conversations with police officers who had shown up (armed and ready) to bust what was clearly a marijuana grow operation, based on the power use of this house (or the fact that the exhaust vent was glowing if you looked down on the neighborhood with an IR camera). Long awkward conversations with definite nerds who had shelving units full of hacked up computers followed.
But what it boils down to is that you have computers that download workunits (chunks of work and the binary to work on them), do some amount of processing on them (between a few hours and a few weeks, typically, though most workunits are on the “hours” side), send the results back, and this is the process of Doing a Science.
SETI (searching for aliens) is no longer, but there are still plenty of other projects doing useful things (like protein folding/simulation), and a few doing (I would argue) less-useful things like looking for ever-larger prime numbers.

Normally, you use your home computers (or work computers with permission), but… what if you wanted to throw in an awful lot of cycles to a project, quickly? Could you? Could you do it using someone else’s money? It turns out, yes, you can!
The Cloud: Someone Else’s Computer
The Cloud really is just piles of (someone else’s) servers, in data centers, with a convenient set of interfaces, providing some more or less useful set of services.

But it’s a lot of computers, and while not actually infinite, it does a really good job of pretending to be so - especially if you don’t have an insane budget.
For the purposes of distributed compute, I don’t care about most of the various services offered by the cloud either. I only care about the virtual machines. And, because distributed, I only care about Linux. Yes, there are some projects that have Windows-only workunits, and those are well covered by plenty of users, so if you’re going to offer something useful, host with Linux.
For the purposes of this post, I’ll be using GCE - Google Compute Engine. Yes, I know Amazon offers compute services, and you can probably do something similar with spot instances over there, but I don’t like Amazon that much.
And, better for this post, Google offers $300 of free cloud credit to new users! It’s literally using someone else’s money to throw a lot of compute at a project!
Preemptible Instances: Someone Else’s Unreliable Computer - For Cheap!
The problem with these computers (especially for distributed compute work) is that they can be really, really expensive. There’s a lot that goes into making a reliable service, and things like migrating VMs between hosts for maintenance (meaning that your VM never gets shut down, even if the hardware needs a reboot or replacement), reliable disk storage, etc… all cost a lot of money.
A 16 core modern (Skylake+) Intel server with 20GB of RAM and 20GB of disk is a painfully expensive $362/month - and that doesn’t make much sense to buy for distributed compute. You can buy a lot of used server hardware and power for that kind of money.
But GCE offers another instance option - “Preemptible.” This means that your instance can be randomly shut down, and will never run more than 24 hours at a time. It’s a “crack filler” instance - if there’s space, your instance will run. If something else needs the space (and is willing to pay more), you get shut down. But, the disk is persistent (so as long as you’re checkpointing, which BOINC does, you can just pick up where you left off). And that 16 core server? Enabling the preemptible option and going to older CPU cores, it’s down to $91.55/mo. That’s quite a bit cheaper, and stretches that $300 credit quite a bit further. You could even run a smaller instance on loose change. Running a dual core AMD instance with 3GB of RAM? Under $13/mo. I’m saving more than that on transportation energy lately!
Benchmarking: The Cheapest of the Cheap
We could just throw any old instance type at the compute - but are they all equally cost effective? What’s the cheapest way to throw compute cycles at a project?
In the interests of not leaving a ton of workunits uncompleted and abandoned, I didn’t actually throw “real” tasks at the benchmarking. I simply used BOINC’s built in benchmarking tools across a wide range of instance types/sizes to find any patterns. This outputs (in syslog, if you’re curious) the per-core Dhrystone and Whetstone benchmarks. I banged up a script to run the benchmarks 10 times and average the results.
For the N1 (“old Intel”) instances, I selected “Skylake or Later” as the CPU platform, just to ensure I was getting consistent CPUs across the tests. N2 instances are Cascade Lake or later, and N2D instances are AMD EPYC Rome processors. I didn’t test E2 instances, as they run on “roughly whatever’s available” and aren’t really intended for this sort of sustained CPU use, as near as I can tell. You might try them and see, but they just don’t seem consistent enough to benchmark and do anything meaningful with.
It might seem that the smallest instances (1 or 2 CPU cores) would be the most effective, but they pay the “OS overhead” repeatedly - you need more RAM across all the instances for the OS, more disk to hold OS files, etc. These costs are something resembling a practical instance - GB of RAM equals CPU cores, and either 10GB of disk, or, for more than 10 cores, 1GB of disk per CPU core.
For the purposes of comparing things, I created a bunch of instances and benchmarked them. They have 1GB of RAM per core, and either 10GB of disk or 1GB per CPU core, whichever is greater. This won’t run some of the more recent Rosetta workunits, but it gives me a consistent base for benchmarking.
First, let’s look at “per-core compute” - does the instance size make a difference in compute-per-core? It turns out, yes, it does!
First, Whetstone - a vintage floating point benchmark that BOINC uses for CPU evaluation. It’s pretty clear that there’s a connection between core count and performance per core, though… old Intel chips are worse at this than the AMD chips. As you add cores, N1 instances get worse, N2 instances hold exactly the same, and the AMD cores get better. Weird.

Does this hold for integer operations in the Dhrystones benchmark? Not really. The only thing that stands out here is that the single-CPU N1 instance outperforms the others - and this makes sense. With all the microarchitectural vulnerabilities across hyperthreads, it’s a good bet that Google isn’t scheduling other VMs on the other virtual core, so the single CPU N1 instance has a “full physical core” and the other stuff is sharing core resources. No real difference here.

But, we need more overhead for single CPU instances. What’s the cost-per-unit-compute in the instances I’ve created, all-in (counting RAM/disk)? Well, let’s look!
On the floating point side, the N2 instances certainly perform well, only beat by a large AMD instance (16 core). The performance boost on extra cores from AMD is certainly helping here, though there’s not quite as huge a difference as I’d expected between instances. The price per performance is remarkably consistent across instances.

On the integer side, the same general trend holds, though the AMD lead here is less. The presumably non-shared core of the single core N1 instance really shows off here.

There’s certainly more to performance than just these benchmarks, but the main takeaway here is that there’s no huge win from any instance type or another.
But… that single core N1 instance looks like it’s a pretty sweet point! You pay for one vCPU, and effectively get two - because it doesn’t seem like it’s sharing hyperthreads with other VMs. Throw in the fact that a small single CPU instance is most likely to “fit in the cracks,” and… well, the only real downside is the maintenance overhead of maintaining more instances!
In terms of CPU years, the big N1/N2D instances are the cheapest per CPU - $88.79/mo for 16 cores, so 4.5 CPU years! The small single core instance is a bit more per CPU-year, but offers an awful lot more compute for the cost.
Creating an Instance
To start the process out, you’ll want to create a preemptible instance - and it’s vitally important that you expand out the options to do this, otherwise there’s no point and you’ll spend a ton!
I’ll be creating that “sweet spot” N1 single CPU instance. Some zones do cost more than others, so pay attention to the cost estimator and make sure you’re using a cheap zone.
How much RAM do you need? “Enough.” Some tasks don’t take much (300MB), so if you want to run those, you can get away with less. Some require more, so add more. Some of the really heavy Rosetta tasks lately require around 2GB (per task!), so to handle those, you’d want 2-3GB per CPU. In general, 2GB per CPU seems to be useful, though you could use less for some projects. If you’re wrong, it’s easy enough to stop the instance, edit it for more RAM, and start it again!
In any case, you’ll want to set the disk space large enough to handle everything. Again, per-task size varies, but 10GB + about 2GB per CPU core should be more than enough. If you’re doing this a lot, why, I bet you’ll optimize things! While you’re sizing your disk, select Ubuntu 18.04 LTS - it’s a good base to use. No, Clear Linux doesn’t really matter for something like this!
You’ll need to expand out the “Management, security, disks, networking, sole tenancy” options to see the preemptible option.

Do it right, for a n1-standard-1 instance with 10GB of disk, and you should see about $7.70/mo. If you’re seeing $25/mo, you’ve forgotten to set the preemptible option! If you want, you can create a custom type with a bit less RAM (2.5GB ought to be fine) and save a bit.

Start it, and you’ll then log in via SSH. You can either do it via the web console, or via the gcloud command if you’re set up that way - find a tutorial if you want to go that route, my goal here isn’t an end to end GCE tutorial. Sorry.
This is a dedicated compute instance, so you’ll want to install boinc - and then change some of the defaults. Some projects are still using 32-bit binaries, so you’ll want the libraries for that as well. On Ubuntu 18.04, something like this should work well for you:
sudo apt update && sudo apt install -y lib32gcc1 lib32ncurses5 lib32stdc++6 lib32z1 lib32stdc++-6-dev boinc-client boinctui
Once BOINC starts, you’re good, right? Nope! You need to tell it that, yes, this whole entire gigantic server is for it’s use, which means overriding a few things in the config.
Set the overrides in /usr/lib/boinc/global_prefs_override.xml and then load them with boinccmd --read_global_prefs_override. You can override anything from the global_prefs file, but I’ll offer this as advice:
<global_preferences>
<disk_max_used_gb>20.0</disk_max_used_gb>
<disk_min_free_gb>0.5</disk_min_free_gb>
<disk_max_used_pct>90.0</disk_max_used_pct>
<ram_max_used_busy_pct>90.0</ram_max_used_busy_pct>
<ram_max_used_idle_pct>90.0</ram_max_used_idle_pct>
</global_preferences>Or, in more convenient form:
printf "<global_preferences>\\n\\
<disk_max_used_gb>20.0</disk_max_used_gb>\\n\\
<disk_min_free_gb>0.5</disk_min_free_gb>\\n\\
<disk_max_used_pct>90.0</disk_max_used_pct>\\n\\
<ram_max_used_busy_pct>90.0</ram_max_used_busy_pct>\\n\\
<ram_max_used_idle_pct>90.0</ram_max_used_idle_pct>\\n\\
</global_preferences>" | sudo tee /var/lib/boinc/global_prefs_override.xml </center>
Don’t Drop Work: Finish Out Before Deleting!
If you’re getting near your $300 freebie credit, or whatever you want to spend, just finish out your work units before terminating the instance. Under the boinctui menu, select the project, then “No new tasks” to prevent it from requesting any new work. Once the stuff is finished, then delete the instance. It’s just not nice to leave half competed workunits lost to the void - yes, they can handle it, but it’s still just kind of being a jerk if you can avoid it.
It doesn’t matter if the instance terminates and restarts - the task will resume. It’s just when you go about deleting the instance that this becomes a problem.

Even Lazier? Use the Startup Script!
If this setup is too much work, just use the startup script field in VM creation!
It’s under the Management tab you have to expand for preemptible instances, and you could just paste the whole blob in! Set your variables as required up at the top, or just use my compute account. I really don’t care about points, I’m just throwing cycles around as I have spare cycles, so it doesn’t matter to me. Yes, this is my weak key.
#!/bin/bash
PROJECT_URL=http://boinc.bakerlab.org/rosetta/
PROJECT_WEAK_KEY=1433420_2338854c377dfe58a6673b5d0961ed1f
apt update
apt install -y lib32gcc1 lib32ncurses5 lib32stdc++6 lib32z1 lib32stdc++-6-dev boinc-client boinctui
cat <<EOF > /var/lib/boinc/global_prefs_override.xml
<global_preferences>
<disk_max_used_gb>20.0</disk_max_used_gb>
<disk_min_free_gb>0.5</disk_min_free_gb>
<disk_max_used_pct>90.0</disk_max_used_pct>
<ram_max_used_busy_pct>90.0</ram_max_used_busy_pct>
<ram_max_used_idle_pct>90.0</ram_max_used_idle_pct>
<\/global_preferences>
EOF
boinccmd --project_attach $PROJECT_URL $PROJECT_WEAK_KEY“I got my instances shut down for cryptocurrency mining!”
If you’re messing around with this, you might get some notification that your instances have been shut down for abuse, and it might mention cryptocurrency mining (because you fire up some instances and peg the CPU out, though the memory use should indicate it’s not really mining). Just tell them what you’re doing, and it should be fine. The concern here actually isn’t cryptocurrency mining - it’s that the people doing cryptocurrency mining had an annoying tendency of using stolen credit cards, and would generate an insane number of (fraudulently created) accounts, use the free credit, run up actual charges, and have it all tied to stolen cards that wouldn’t work when the time came to bill, or that would get chargebacks.
If you’ve got a long standing Google account, but haven’t used GCE, there’s no harm in what you’re doing, and they should clear stuff out quickly enough. But, hopefully, it won’t be an issue.
Enjoy Compute!
Yes. This whole thing is a bit silly. Spending (other people’s money) to buy cloud compute time to throw cycles at distributed projects. But, really, are you doing anything else right now?
It’s a fun little way to beat boredom!
On Covid
You might notice (by this post) that I’m back, after having taken a very nice couple weeks off posting. In that time period, the entire world has come apart at the seams, and I regret to report that I did not do a particularly good job of avoiding modern technology infrastructures and such during my Lent break. Unfortunately, “knowing that our state is shutting down” seemed more important than a self imposed break on connectivity. Though I’ll admit to following more news than relevant for a while.
I’m very, very glad to be on a few acres in the country, in a mostly rural state during this. Far nicer than Seattle, and we have an awful lot of space to run around on/kick the kids out to/move rocks on. It beats sitting inside by an awful lot.
How does all this end? Not well, sadly. Air travel is down to 1950s levels, though we’re still flying a lot of empty planes around empty skies. The quiet is pretty nice. Anyone in doubt that the emperor is naked and clueless should be realizing this, though plenty will continue insisting at the top of their lungs that the clothing is beautiful, because political party uber alles - which is a common trait of decaying empires. And our society makes another good solid plunge down the staircase of catabolic collapse.
It’s also a very, very good test case of the LESS principles - “Less Energy, Stuff, and Stimulation.” It’s a likely feature of the coming future, so how’s it going? Anything that can’t go on forever won’t - and exponential growth on a finite planet can’t go on forever, so it won’t. No, I don’t think that the various handwaves around this (asteroid mining, planetary colonization, etc) will remain anything beyond science fiction. If you disagree, go spend a week or two playing Kerbal Space Program, and then realize that the whole Kerbin system is radically nerfed compared to our actual solar system.
Comments
Comments are handled on my Discourse forum - you'll need to create an account there to post comments.If you've found this post useful, insightful, or informative, why not support me on Ko-fi? And if you'd like to be notified of new posts (I post every two weeks), you can follow my blog via email! Of course, if you like RSS, I support that too.





{kind=link}